-
[논문 리뷰] DeepPose: Human Pose Estimation via Deep Neural NetworksPaper Review/Computer Vision 2022. 2. 7. 16:33
Abstract
Convolutional Deep Neural Networks(DNN)을 기반으로 한 human pose 방법을 제안한다. Pose estimation은 body joint(신체 관절)에 대한 DNN 기반 회귀 문제로 해결한다. 이 접근 방식은 전체적인 방식으로 pose에 대해 추론할 수 있는 장점이 있으며 이를 단순하지만 강력하게 공식화했다.
1. Introduction

인체 관절의 localization 문제로 정의되는 human pose estimation 문제를 joint 회귀 문제로 공식화하고 DNN 네트워크에서 캐스팅하는 방법을 보여준다. 이 방법에는 두 가지 장점이 있다.
1. DNN은 각 신체 관절의 전체 context를 캡처할 수 있다. 각 joint regressor는 전체 이미지를 신호로 사용한다.
2. 이 접근방식은 그래픽 모델에 기반한 방법보다 공식화하기가 훨씬 간단하다. 이전 모델들은 각 관절마다 feature representation과 detector를 만들어 합치는 방식이지만 이 모델은 단일 신경망으로 모든 관절의 위치를 예측할 수 있다.
또한, cascade DNN-based pose predictors를 제안한다. 이러한 계단식(cascade)으로 인해 관절 위치의 정밀도를 높일 수 있다. 초기 pose estimation부터 시작하여 전체 이미지를 기반으로 더 높은 해상도의 하위(부분) 이미지를 사용하여 관절 위치 예측을 조정하는 DNN-based regressor까지 학습한다.
3. Deep Learning Model for Pose Estimation
먼저, 입력 이미지를 DNN에 통과시켜 k개의 관절에 대한 예측값(pose vector)을 도출한다.
Pose를 표현하기 위해, k개의 신체 관절의 위치를 y_i로 정의된 pose vector로 인코딩한다. 라벨된 이미지는 (x, y)로 표시된다. 여기서 x는 이미지 데이터를 의미하고 y는 ground truth pose vector이다. y_i는 i번째 joint의 x,y 좌표를 포함한다.

또한, 관절의 좌표가 이미지 좌표 내에 있기 때문에, 신체 또는 그 일부를 묶는 box b로 정규화하는 것이 좋다. 간단한 경우 box는 전체 이미지를 나타낼 수 있다. 이러한 상자는 b = (b_c(중심), b_w(너비), b_h(높이))로 정의된다. 각 관절의 x, y 좌표와 중심점 간의 차를 구하고 각각을 너비와 높이로 나누어 주면 0과 1 사이의 값으로 정규화를 시킬 수 있다. 이후, y_i의 좌표를 아래식처럼 정규화한 N(yi;b)로 사용된다.
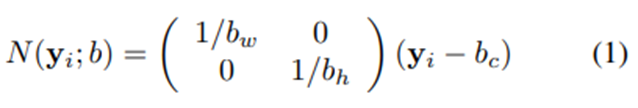
세미콜론 이후의 변수는 파라미터를 의미 
마지막으로, N(x; b)을 사용하여 bounding box b에 의해 잘려진 이미지 x를 나타내며, 이는 box를 통해 이미지를 정규화한다. 간단하게 하기 위해서, b를 전체 이미지 box인 N(·) 정규화로 아래와 같은 방식으로 나타낸다.

3.1 Pose Estimation as DNN-based Regression
이 논문에서는 pose estimation 문제를 회귀로 취급한다. 여기서 우리는 이미지 x에 대해 정규화된 pose vector로 회귀하는 함수 ψ(x;θ)를 훈련하고 사용한다. 여기서 θ는 모델의 파라미터를 나타낸다. 그리고 각 이미지 x에 대해 정규화된 pose vector를 회귀하여 pose prediction y* 를 읽는다. 즉, 이미지를 ψ에 넣어 네트워크를 거치고 정규화된 pose vector를 원래 이미지의 좌표계로 다시 변환하는 것이다.
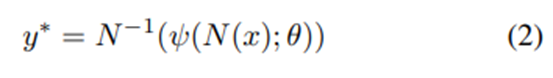
이미지의 절대 좌표값으로 변환 이러한 컨볼루션 네트워크는 여러 계층으로 구성되며, 각각은 non-linear transformation 다음에 linear transformation이 뒤따른다. 첫 번째 layer는 미리 정의된 크기의 이미지를 입력으로 사용하며 픽셀 수에 3개의 color channel을 곱한 크기와 같다. 마지막 layer는 회귀의 목표값을 출력하는데, 이 경우 2k joint 좌표(x, y)를 출력한다.
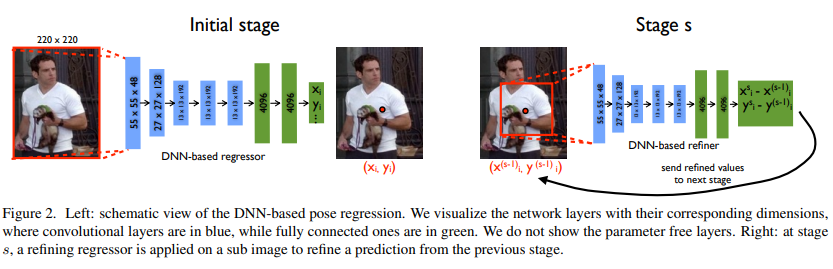
네트워크는 7개의 계층으로 구성되어 있다. C는 conv layer, LRN은 local response normalization layer, P 는 pooling layer, F는 fc layer를 나타낸다. C 및 F layer만 학습 가능한 파라미터를 포함하고 나머지는 파라미터가 없다.
더보기# LRN
CNN 모델에서 한 pixel값이 특히 강한 값을 가지면 convolution연산을 수행할 때 과적합이 일어날 수 있다. 따라서, 그 pixel 주변이나 같은 위치의 다른 채널의 값들을 square-sum하여 과적합을 막는 방법이다.
처음 2개의 C층은 필터 크기가 11 × 11, 5 × 5이고 나머지 3개는 3 × 3이며, pooling은 3개의 layer 이후에 적용된다. 네트워크에 입력되는 이미지는 220 × 220이며, 4 stride을 통해 네트워크로 공급된다. 위 모델의 총 파라미터 수는 약 40M이다.
Training.
예측과 실제 pose vector 사이의 L2 거리(유클리드 거리)를 최소화하도록 훈련시키기 위해 마지막 layer에서 linear regression을 훈련한다. Ground truth pose vector는 이미지 좌표로 정의되고 포즈 크기가 이미지마다 다르기 때문에 훈련 세트 D를 정규화한다.

그런 다음 최적의 네트워크 매개변수를 얻기 위한 L2 손실은 다음과 같다.

오차제곱합과 같은 모양 위의 파라미터 implement는 분산 온라인 구현에서 역전파를 사용하는 데 최적화되어 있다. 크기가 128인 각 미니 배치에 대해 SGD 업데이트가 계산된다. Learning rate는 0.0005로 설정되어 있다. 모델의 파라미터 수가 많고 사용된 데이터 세트가 상대적으로 작기 때문에, 무작위로 변환된 이미지 크롭을 사용하여 데이터를 늘린다. F layer에 대한 드롭아웃 정규화는 0.6으로 세팅한다.
3.2 Cascade of Pose Regressors
앞 부분의 pose 공식은 joint estimation이 전체 이미지를 기반으로 하므로 context에 의존한다는 장점이 있다. 그러나 220 × 220의 고정 입력 크기로 인해 네트워크는 세부 정보를 볼 수 있는 용량이 제한된다. 이는 pose를 추정하는데 필요하지만 항상 신체 관절을 정확하게 위치시키기에는 불충분하다. 이렇게 하면 이미 많은 수의 파라미터가 증가하므로 입력 크기를 늘리기 어렵다. 더 나은 정밀도를 달성하기 위해 cascade 방식의 pose regressor를 훈련할 것을 제안한다.
첫 번째 단계에서 cascade는 초기 pose를 추정함으로써 시작된다. 후속 단계에서는 이전 단계에서 실제 위치로의 관절 위치의 변위를 예측하기 위해 추가 DNN regressor를 훈련한다. 즉, 이 cascade 아이디어는 예측 좌표 주변으로 바운딩 박스를 다시 그리고, crop하여 다시 DNN모델을 통과시키는 방식이다.
또한 각 후속 단계는 이미지의 관련된 부분에 초점을 맞추기 위해 예측된 관절 위치를 사용한다. 하위 이미지는 이전 단계에서 예측된 관절 위치 주위에 crop되고 이 joint에 대한 pose displacement regressor가 이 하위 이미지에 적용된다. 이러한 방식으로 후속 pose regressor는 더 높은 해상도의 이미지를 보고 더 미세한 스케일을 위한 특징을 학습하여 궁극적으로 더 높은 정밀도로 이어진다.
Cascade의 모든 stage에 동일한 네트워크 아키텍처를 사용하지만 다른 네트워크 파라미터를 학습한다. 총 S cascade stage의 각 stage s에 대해 학습된 네트워크 파라미터를 θs 으로 나타낸다. 따라서 pose displacement regressor는 ψ(x; θs)를 읽는다.주어진 joint location y_i을 수정하기 위해 yi 주변의 하위 이미지를 포착하는 새로운 관절 bounding box bi를 고려한다.


Pose의 직경 diam(y)는 왼쪽 어깨와 오른쪽 엉덩이와 같은 인간 몸통의 반대 관절 사이의 거리로 정의되며, 구체적인 자세 정의와 데이터세트에 따라 달라진다.
위의 표기법을 사용해 s = 1 단계에서 전체 이미지를 포함하거나 detector에 의해 얻어진 bounding box b^0으로 초기 pose를 얻는다.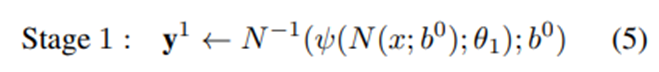
각 후속 단계 s ≥ 2에서, 모든 관절 i = {1, . . . , k}에 대해, 먼저 이전 단계 (s - 1)에 의해 정의된 하위 이미지에 regressor를 적용하여 refinement displacement y^s_i - y^(s-1)_i로 회귀한다.
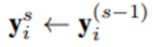
그리고 나서, 새로운 joint box b^s_i를 예상한다.

1. x에서 bounding box로 얻은 정규화 이미지
2. 정규화된 부분 이미지에서 pose vector 추정
3. 추정된 pose vector을 절대적인 이미지 좌표로 변환
Training.
딥 러닝 방법은 용량이 크기 때문에 각 이미지와 관절에 대해 여러 정규화를 사용하여 훈련 데이터를 증가시킨다. 이전 단계의 예측을 사용하고 시뮬레이션된 예측을 같이 이용한다. 이것은 훈련 데이터의 모든 예에 걸쳐 관측된 변위(y^(s-1)_i - y)의 평균과 분산과 동일한 평균과 분산을 가진 2차원 정규 분포 N^(s-1)_i에서 무작위로 샘플링된 벡터에 의해 관절 i에 대한 ground-truth 위치를 임의로 이동함으로써 이루어진다. 전체 증강 훈련 데이터는 균일하게 원본 데이터에서 예시와 관절을 먼저 샘플링한 다음 N (s-1) i에서 샘플링된 변위 δ를 기반으로 시뮬레이션 예측을 생성하여 정의할 수 있다.

즉, Ds_A는 bounding box로부터 crop된 영역을 의미한다. Cascade stage s에 대한 훈련 목표는 각 joint에 대해 올바른 정규화를 사용하도록 수행된다.

파라미터의 최적값을 얻기 위한 L2손실 
4. Empirical Evaluation
4.1 Setup
Datasets.
첫 번째 데이터 세트는 FLIC(Frames Labeled In Cinema)로, 인기 할리우드 영화에서 얻은 4000개의 훈련 이미지와 1000개의 테스트 이미지로 구성되어 있다. 그 이미지들은 다양한 포즈와 특히 다양한 옷을 입은 사람들을 담고 있다. 사람마다 10개의 상반신 관절이 라벨로 표시되어 있다.
두 번째 데이터 세트는 Leeds Sports Dataset이다. 11000개의 훈련 영상과 1000개의 테스트 영상이 포함되어 있다. 이것들은 스포츠 활동에서 나온 이미지들이다. 대다수의 사람들은 150픽셀의 높이를 가지고 있어 pose estimation이 더욱 어렵다. 이 데이터 집합에서 각 사람에 대해 전신에는 총 14개의 관절이 레이블링된다.
위의 모든 데이터 세트에 대해, 우리는 포즈 y의 직경을 반대쪽에서 어깨와 엉덩이 사이의 거리로 정의하고 그것을 diam(y)로 표시한다.Metrics.
두 가지 평가 지표를 사용한다. PCP(Percent of Correct Parts)는 팔다리의 검출률을 측정한다. 여기서 두 개의 예상 관절 위치와 실제 사지 관절 위치 사이의 거리가 사지 길이의 최대 절반인 경우 사지가 검출된 것으로 간주된다. 하지만 PCP는 낮은 팔과 같은 짧은 팔다리에 불이익을 주는 단점이 있다.
이러한 단점을 해결하기 위해, 예측된 관절과 실제 관절 사이의 거리가 torso diameter의 특정 부분 내에 있을 경우 관절이 검출되는 것으로 간주한다. 이 부분을 통해 다양한 정도의 localization precision에 대한 detection rate을 얻을 수 있다. 이 측정법은 모든 관절에 대한 검출 기준이 동일한 거리 임계값에 근거하기 때문에 PCP의 단점을 완화한다. 이 메트릭을 PDJ(검출된 관절 비율)라고 한다.더보기torso diameter is defined as the distance between left shoulder and right hip of each ground-truth pose
Experimental Details.
모든 실험에서 동일한 네트워크 아키텍처를 사용한다. FLIC의 body detector를 사용하여 인체 경계 상자의 대략적인 추정치를 초기에 구한다. face detector를 기반으로 하며, 탐지된 face box가 고정된 스칼라에 의해 확대된다. 이 스칼라는 레이블이 지정된 모든 관절을 포함하는 훈련 데이터에 따라 결정된다.
알고리즘 하이퍼 파라미터를 결정하기 위해 두 데이터 세트에 대해 50개의 작은 이미지 세트를 사용한다. 파라미터의 최적성을 측정하기 위해 모든 관절에서 0.2에서 PDJ에 대한 평균을 사용한다. 정제 조인트 경계 상자의 크기를 포즈 크기의 일부로 정의하는 σ는 다음과 같이 결정된다. FLIC에 대해 LSP에 대해 값 {0.8, 1.0, 1.2}을 탐색한 후 {1.5, 1.7, 2.0, 2.3}을 사용한 후 σ = 1.0을 선택했다. Cascade stage S의 수는 알고리즘이 홀드아웃 세트에서 개선을 멈출 때까지 훈련 단계에 의해 S = 3으로 결정된다.4.2 Results and Discussion
Comparisons.
그림 1에서 PCP 평가지표를 사용하여 LSP를 비교한다. 우리는 가장 어려운 네 가지 사지(하부 및 상부 팔과 다리)에 대한 결과와 비교된 모든 알고리즘에 대한 이들 팔다리의 평균 값을 보여준다.
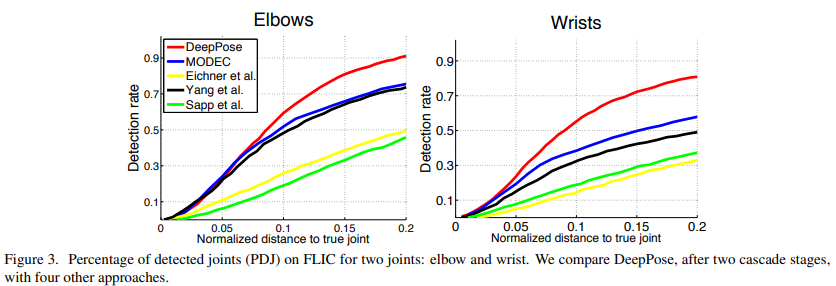
관절의 정확한 위치 파악 없이 거친 자세를 감지하는 경우 정밀도가 낮은 영역에서 성능이 더 좋다. FLIC에서는 정규화된 거리 0.2에서 팔꿈치와 손목에 대해 0.15와 0.2만큼 검출률이 증가한다.
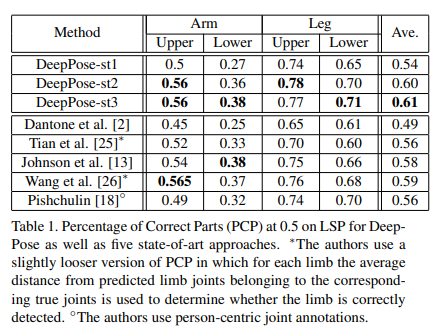
또한 이 접근 방식은 LSP의 스포츠 이미지와 같은 무거운 영화 데이터뿐만 아니라 외양 모두에 잘 작동한다.
Effects of cascade-based refinement.
단일 DNN 기반 joint regressor는 대략적인 joint location를 제공한다. 그러나 더 높은 정밀도를 얻기 위해서는 초기 예측을 개선하는 역할을 하는 cascade의 후속 단계가 가장 중요하다. 이를 확인하기 위해 그림 5에서 초기 예측에 대해 서로 다른 정밀도에서 joint detection과 두 가지 후속 cascade stage를 제시한다.

Cross-dataset Generalization.
알고리즘의 일반화 속성을 평가하기 위해 두 개의 관련 데이터 세트에서 LSP 및 FLIC에 대해 훈련된 모델을 사용했다. 이 데이터 세트는 LSP와 유사하며 스포츠를 하는 사람들을 포함하고 있지만, 다른 활동에 참여하는 개인 사진 컬렉션의 많은 사람들을 포함하고 있다.

Example poses.
알고리즘의 성능을 더 잘 이해하기 위해 그림 8에서 LSP의 이미지에 추정된 포즈 샘플을 시각화한다. 알고리즘은 거꾸로 된 사람(1행, 1열), 심각한 전방 단축(1행, 3열), 비정상적인 자세(3행, 5열), 3행, 2, 6열의 막힌 팔로서 가려진 사지(3헹, 3열) 등 다양한 조건에서 대부분의 관절에 대해 올바른 자세를 취할 수 있다.

5. Conclusion
Human pose estimation에 대한 심층 신경망(DNN)의 첫 번째 응용 프로그램을 제시한다. 문제를 joint 좌표에 대한 DNN 기반 회귀와 제시된 그러한 regressor를 cascade 방식으로 공식화하면 context를 포착하고 pose에 대한 전체적인 추론을 할 수 있는 장점이 있다.
또한, 일반 컨볼루션 신경망을 사용하여 localization의 다른 작업에 적용할 수 있음을 보여준다. 향후, 일반적으로 localization 문제, 특히 pose estimation에 더 잘 맞춰질 수 있는 새로운 아키텍처를 조사할 계획이라고 한다.논문
https://arxiv.org/abs/1312.4659
참고
https://ctkim.tistory.com/108'Paper Review > Computer Vision' 카테고리의 다른 글