-
[논문 리뷰] SyncNet - Out of time: automated lip sync in the wild (2016)Paper Review/Face 2022. 9. 28. 16:34
얼굴 생성 task에서 기존의 PSNR, SSIM 등의 영상 품질 평가 지표와는 다르게 Lip-Sync를 평가하는 프레임워크인 LSE-D, LES-C의 바탕이 된 SyncNet에 대한 논문이다.
해당 논문의 주요 기여점은 ConvNet 아키텍처와 오디오와 입 모양 사이의 공동 임베딩을 레이블링된 데이터 없이 TV 방송으로부터 학습할 수 있도록 하는 end-to-end 데이터 처리 파이프라인이다.
이 솔루션은 크게 3가지로 활용될 수 있으며 거의 100%에 근접한 성능을 보인다.
- Determining lip-sync error in videos
- Detecting the speaker in a scene with multiple faces
- Lip Reading
이전의 audio-video syncronisation 문제에서 영상과 타임스탬프를 활용하거나, 음소 인식을 위주로 판단하고 학습한다. 하지만, 논문에서는 라벨링 없는 video 데이터의 representation을 통해 lip-sync를 판단할 수 있는 아키텍처를 제안한다.
# Representations and Architecture
SyncNet은 오디오와 비디오 입력의 0.2s의 클립을 선택한다. 논문에서는 일반적으로 데이터셋의 영상에서의 lip-sync는 syncronisation이 잘 되어있다고 가정하였다. 네트워크는 선택한 클립의 오디오, 비디오의 2가지 asymmetric stream으로 구성된다.

Input Representation - Audio, Video # - 1. Audio stream
Audio stream은 MFCC 값을 입력으로 받는다. 해당 값은 0.2s의 입력 신호로부터 20개의 time step을 제공한다. 각 time step마다 13개의 mel frequency band가 사용된다.
해당 stream의 아키텍처는 VGG-M에 기반하며, 차원에 입력에 따라 필터 크기를 수정하였다. VGG-M은 이미지 인식을 위한 CNN으로써, 오디오 데이터를 13(mel frequency band) X 20(time step) 로 수정하였다고 한다.
# - 2. Visual stream
Visual stream은 sequence of mouth region을 그레이스케일의 영상으로 입력받는다. 입력 차원은 25Hz 프레임 영상에서 0.2s에 해당하는 5프레임에 대한 111(w) X 111(h) X 5(t) 이다.
해당 stream의 아키텍처는 visual speech recognition에 사용된 아키텍처를 기반으로 한다. 해당 아키텍처에서 conv1 필터가 5 channel을 입력으로 받도록 수정하였다고 한다.
[ Chung, J.S., Zisserman, A.: Lip reading in the wild. In: Proc. ACCV (2016)의 아키텍처 사용 ]
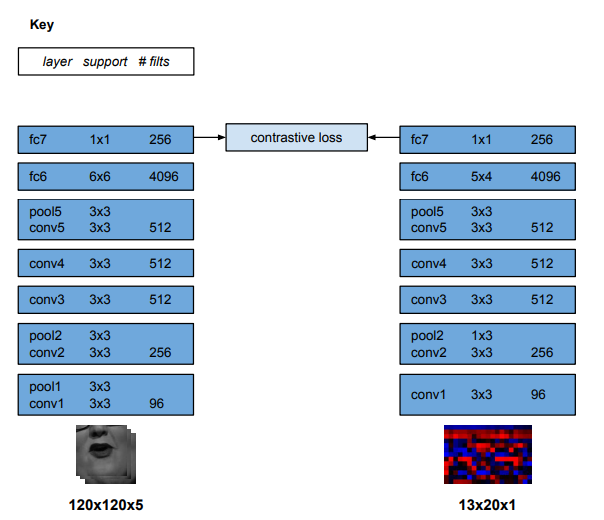
SyncNet Architecture. # Loss Function
아키텍처의 train 목표는 audio, visual stream의 output이 genuine pair에 대해 유사하고, fake pair에 대해서는 다르다는 것이다. 따라서 각 네트워크의 출력 사이의 유클리드 거리를 통해 구할 수 있다고 한다.
따라서, 아래의 contrastive loss를 사용한다. v,a는 각 visual, audio stream에 대한 fc7층의 벡터이다. y는 0 또는 1의 값으로 각 스트림 입력 사이의 이진 유사성을 의미한다.
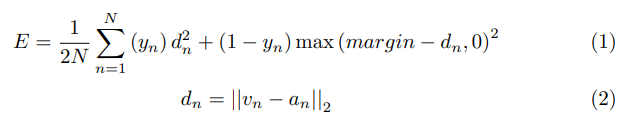
# Training
네트워크의 가중치는 SGD를 통해 학습되며 두 stream은 동시에 학습된다.
데이터셋은 BBC 뉴스 비디오를 사용했으며, 각 프레임마다 HOG-based face detection 방법을 사용하였고, KLT tracker를 사용하여, face detection을 그룹화 했다고 한다. 또한, 오디오가 하나이기 때문에 두 개 이상의 얼굴이 나오는 클립은 사용하지 않았다.

Generating the audio-visual datasets. 해당 데이터를 수집한뒤 훈련 데이터를 준비한다. 학습을 위한 Genuine audio-video pair와 Fake audio-video pair를 아래와 같은 방법으로 지정한다. 선택된 0.2s의 genuine pair와 최대 2초 거리에 있는 무작위 audio를 통해 fake pair를 만든다. 따라서, 같은 클립의 audio를 통해 alignment를 인식하는 것을 학습한다.

Obtaining genuine, fake pairs. 이렇게 수집된 데이터셋에는 더빙이나 싱크가 안맞는 데이터가 포함될 수 있어, 네트워크는 초기에 genuine pair에 있는 이러한 false positive를 버리는데 사용된다고 한다. 이후 새로운 데이터에 대해 재 학습을 진행한다.
# Lip-Sync Error
lip-sync error를 판단하는 방법은 다음과 같다. 각 클립에 대해 5프레임에 대한 video feature와 앞뒤 1s 범위의 audio feature 샘플의 거리를 계산한다. 이렇게 각 클립마다 수집된 값들의 평균을 구한다. 이에 대한 평가는 사람이 감지할 수 없는 경우 sync가 성공한 것으로 간주하였다고 한다.
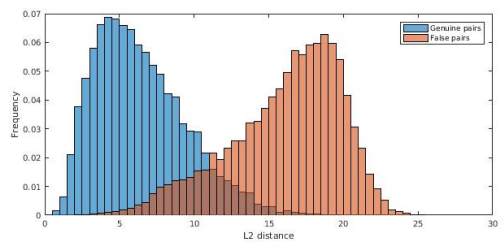
genuine, fake pair에 대한 feature distance 분포. 
사람이 감지할 수 없는 경우에 대한 정확도. # Confidence Score 활용
이 논문에서는 다수의 얼굴에서 speaker를 결정하기 위해 confidence score를 사용하였다. (이 방법이 추후에 LSE-C라는 지표로 발전하였다.)
저자는 confidence score of sycn error를 앞서 구한 유클리드 거리의 최소값과 중위값 사이의 차이로 정의하였다. 영상 내에서 speaker는 오디오와 비디오의 대응성이 가장 높은 얼굴로, 높은 confidence score를 보이게 된다.
해당 내용에 대한 test로 f1 score를 비교하였을때, 거의 100%에 가까운 결과를 보여준다.

f1 score on the Columbia speaker detection dataset. # Conclusion
이러한 방법론을 사용하여 lip-sync error를 평가할 수 있으며, 서로 다른 도메인에서 상관된 데이터의 joint embedding을 학습하는데 필요한 모든 문제로 활용될 수 있다고 한다.
참고 논문 : Out of time: automated lip sync in the wild (2016)
'Paper Review > Face' 카테고리의 다른 글
[논문 리뷰] Attention-Based Lip Audio-Visual Synthesis for Talking Face Generation in the Wild (2022) (0) 2022.10.14 Talking head Generation Evaluation Measures (0) 2022.10.06 Face Generative Model Metric - LSE-D, LSE-C (0) 2022.09.28 [DeepFake] 관련 논문 정리 (0) 2022.02.24 [Deepfake] 간단 개념 정리 (0) 2022.02.24