-
[논문 리뷰] Attention is All you Need (2017)Paper Review/NLP 2022. 4. 4. 11:45
1. Introduction
Sequence Modeling, Transduction Problems
-> RNN, long short-term memory, gated RNN
-> Encoder, Decoder architecture의 발전
Recurrent model에서 입출력 sequence의 position에 따라 순차적으로 계산이 수행되어야 함
-> Sequence의 길이가 길어지면 메모리와 연산 효율에 대한 문제가 발생

Recurrent Model ex. Attention Mechanism은 입출력 sequence의 거리에 상관 없이 의존성을 모델링할 수 있도록 한다.
이 논문에서는 이러한 Attention mechanism에 전적으로 의존하는 Transformer라는 모델 아키텍쳐를 recurrence를 없애고 입출력 간의 global dependencies를 이끌어낼 수 있다.
각 단어 중 모델의 attention 파악 2. Model Architecture
Transformer는 encoder, decoder에 대해 적층된 self-attention과 fully-connected layer를 통한 아키텍쳐이다.
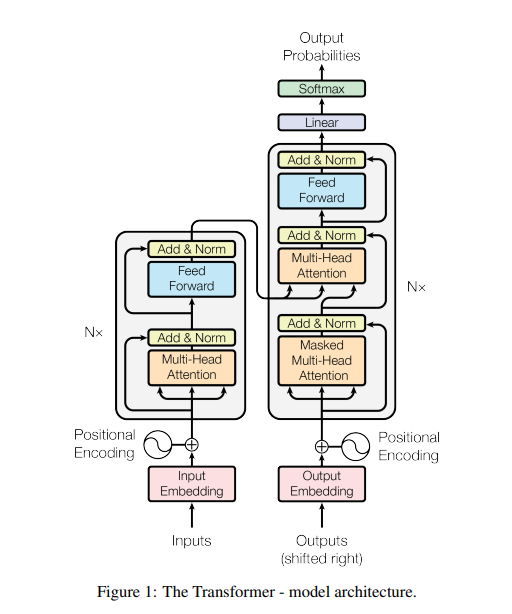
2.1 Endcoder and Decoder stacks
# Encoder
N = 6개의 동일한 레이어으로 구성된다. 각 레이어에는 multi-head self-attention mechanism, fully connected feed-forward network, 2개의 서브레이어가 존재한다. 서브 레이어에 residual connection과 layer normalization을 사용한다. 이러한 residual connection을 용이하게 하기 위해, 모델의 모든 서브 레이어의 출력은 512차원으로 설정한다.
# Decoder
N = 6개의 동일한 레이어으로 구성된다. Decoder는 encoder의 2개의 서브 레이어에 추가적으로 encoder의 출력에 대해 multi-head attention을 수행하는 3번째 서브 레이어를 사용한다. Decoder에도 각 서브 레이어에 residual connection과 layer normalization를 사용한다. 또한 self-attention 서브레이어를 수정하여 Masking을 통해 output의 위치가 다른 위치로 이동하는 것을 방지한다.
2.2 Attention
Attention function은 query, key-value 쌍의 집합을 출력에 매핑한다. 출력은 값의 가중치 합계로 계산되며, 각 값에 할당된 가중치는 query의 해당하는 key와의 compatibility funciton에 의해 계산된다.
2.2.1 Scaled Dot-product Attention
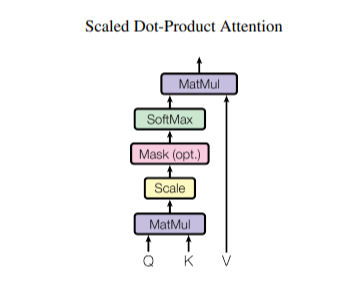
모델에서 특별한 attention을 "Scaled Dot-Product Attention"이라고 부르며, 입력은 차원 d_k의 query와 차원 d_v의 key로 이뤄진다. 이 과정은 key와 query의 벡터에 대한 연산을 통해 나머지 value의 정보를 추출하는 과정으로 볼 수 있다.

먼저, key와 query의 Dot-product를 계산하고, 값에 대한 가중치를 얻기 위해 softmax를 적용한다. 이 과정을 통해 query와 유사한 key의 확률을 얻을 수 있다. 이후, 확률값과 value 벡터를 dot-product를 계산한다면 원하는 정보를 추출할 수 있다.
더보기Query : 영향을 받는 단어를 나타내는 변수 Key : 영향을 주는 단어를 나타내는 변수 Value : 영향에 대한 가중치를 나타내는 변수추가적으로, dot-product 연산 후 차원에 대해 scaling을 수행하는데 0 근처에서 gradient가 높고, 높은 값들에 대해 낮은 gradient를 보이는 softmax의 특징 때문에 scaling을 통해 모든 값들이 0 근처로 오도록 만든다고 한다.
2.2.2 Multi-head Attention

Single attention function을 사용하는 것보다 query, key, value의 각 차원에 대해 학습된 후 concat하여 linear function을 통해 매핑하는 것이 벡터들의 크기를 줄이고 병렬처리에 더 도움이 된다고 한다. 즉, 각각의 query, key, value(head)을 h개로 나눈 값들의 attention의 값들을 구하고 concat하는 과정을 거친다.

이 작업에서는 8개의 병렬 attention layer 또는 head를 사용한다. 이 경우 각각 d_k = d_v = d_model/h = 64를 사용한다. 각 head의 개수로 나누어 dimension이 감소하기 때문에, computational cost는 single head attention과 유사하다.
2.2.3 Applications of attention in our model
Transformer는 다음 세 가지 방법으로 multi-head attention을 사용한다.
• Encoder-Decoder Attention
해당 레이어에서는 query는 이전 decoder 레이어에서, key와 value는 encoder의 출력에서 가져온다. 이로 인해 decoder의 모든 position이 입력 sequence, 즉 encoder의 모든 position값을 참조함으로써 decoder의 sequence와 encoder의 sequence 간의 상관관계를 학습할 수 있다.
• EncoderEncoder에는 self-attention 레이어가 포함되어 있다. Self-attention 레이어에서는 모든 key, value, query를 같은 encoder에서 가져온다. Encoder 내의 각 position은 encoder의 이전 레이어 내의 모든 position을 참조할 수 있다.
• Decoder마찬가지로 decoder의 self-attention 레이어에서는 decoder 내의 각 position이 decoder의 모든 position을 참조할 수 있다. Decoder에서 왼쪽으로 정보가 흐르지 않도록 auto-regressive property를 보존해야 한다. 따라서, 잘못된 connection에 해당하는 softmax 입력의 모든 값을 masking(-θ로 설정)하여 scaled dot-product attention을 구현한다.
2.3 Position-wise Feed-Forwad Networks
Attention 서브 레이어 외에 encoder와 decoder의 각 레이어에는 fully connected feed-forward network가 포함된다.

이러한 linear transformation은 여러 position에서 동일하지만 레이어마다 다른 파라미터를 사용합니다. 입출력의 차원은 d_model = 512이며, 내부 레이어의 차원은 d_f f = 2048이다.
2.4 Positional encoding
해당 모델은 recurrence와 convolution을 포함하지 않기 때문에 모델이 sequence의 순서를 이용하기 위해서는 sequence에서 토큰의 상대적인 position 또는 절대적인 position에 대한 정보를 주입해야 한다. 이를 위해 encoder와 decoder 하단에 있는 입력 임베딩에 "positional encoding"을 추가한다. Positional encoding은 임베딩과 동일한 차원 d모델을 가지므로 두 개의 합연산이 가능하다.

이 작업에서는 다양한 frequency의 사인 및 코사인 함수를 사용한다.

여기서 pos는 position이고 i는 차원을 의미한다. 즉, positional encoding의 각 차원은 사인파에 대응하며 파장은 2µ에서 10000·2µ까지의 기하급수를 형성한다. 고정 offset k에 대해 PE_pos+k는 PE_pos의 선형 함수로 표현될 수 있기 때문에 모델이 상대적인 position으로 쉽게 참조하는 것을 배울 수 있도록 이 함수를 선택했다고 한다.
paper
https://proceedings.neurips.cc/paper/2017/hash/3f5ee243547dee91fbd053c1c4a845aa-Abstract.html