-
[논문 리뷰] GDB: Gated convolutions-based Document Binarization (2023)Paper Review/Generative Model 2023. 2. 20. 20:21
Abstract
Document Binarization은 문서 분석 작업의 핵심 pre-processing 단계이다. 그러나 기존 방법은 주로 vanila convolution의 fair-treatment 특성과 boundary related 정보를 포함하지 않는 stroke edges의 추출로 인해 edge를 미세하게 추출할 수 없다. 본 논문에서는 text 추출을 gating value 학습으로 공식화하고 부정확한 stroke edge extraction 문제를 해결하기 위해 end-to-end gated convolutions-based network(GDB)를 제안한다. Gated convolution은 다른 attention으로 stroke의 feature를 선택적으로 추출하기 위해 적용된다. 제안하는 프레임워크는 두 단계로 구성된다. 첫째, extra edge branch를 토함하는 coarse sub-network는 priori mask와 edge를 통해 정밀한 feature map을 얻도록 학습된다. 둘째로, refinement sub-network에서는 sharp edge를 기반으로 하는 gated convolution에 의해 첫 번째 sub-network의 output을 refine하기 위해 계단식(cascaded)으로 연결된다. Global information을 위해 GDB에는 local 및 global feature를 결합하는 multiscale operation도 포함된다.
1. Introduction
Document Binarization는 문서 이미지의 각 pixel을 foreground text, 또는 background로 분류하는 작업이다. 필수적인 전처리 단계로서, 작업의 결과는 OCR, 문서 레이아웃 분석, page segmentation을 포함한 많은 문서 분석 작업의 성능에 영향을 미친다. 이러한 문서는 일반적으로 smear, broken holes, crease, faint ink, uneven strokes, 등의 다양한 노이즈를 갖는다.문서 이진화의 주요 문제는 이러한 degradated 문서 이미지에서 fine stroke edge를 추출하는 것이다. 문서의 글꼴, 필기구, 문자 크기가 다르기 때문에 추출이 더욱 어렵다.
일반적으로, 최근 방법은 크게 두 가지로 나눌 수 있다. 첫 번째 방법은 adaptive threshold를 기반으로 한다. Edge detection, background estimation, histogram analysis 등이 속한다. 두 번째 방법은 주로 fully convolutional network를 기반으로 한다. Document binarization의 경우, stroke edge는 threshold를 계산하기 위한 강력한 텍스트 indication으로 활용된다. 하지만, 다양한 유형의 degradation으로 인해 stroke edge를 정확하게 탐지하는 것이 어렵다. 기존 FCN 기반 방법은 이진화를 위해 vanila convolution을 사용하며, stroke edge는 image 내의 주변 feature과 동일하게 처리된다. 이는 네트워크에서 stroke dege에 대해 집중하지 못하도록 한다. 또한 기존의 모든 딥 러닝 기반 방법은 stroke의 boundary 관련 정보를 stroke edge extraction에 충분히 사용하지 않는다.
Gated convolution의 특성에서 영감을 받아 이러한 문제를 고려하여 stroke edge extraction을 gating value의 학습으로 변환하였다. Semantic segmentation에서 좋은 성능을 보이는 Gated convolution을 적용하여 stroke의 feature를 선택적으로 추출한다. Feature를 전파하는 동안 gated convolution은 학습된 gating value를 통해 valid information과 invalid information을 구별한다. 따라서 figure 1.(f)와 같이 학습된 gating value가 stroke edge에 초점을 맞추게 되며, 이를 통해 정확하게 stroke edge를 추출할 수 있다. Gating은 stroke edge를 제외한 noise가 많은 feature를 필터링하게 된다.
이 논문에서는 document binarization을 위한 Gated convolution-based network(GDB)를 제안한다. 이 네트워크는 coarse-to-refine generator와 2개의 discriminator로 설계된다. 먼저, priori mask와 edge를 통해 더 정학한 feature map을 얻기 위해 extra edge brance 가 있는 coarse sub-network을 학습시킨다. 또한, local 및 global feature를 결합한 multiscale operation을 병렬로 처리한다. 두번째로, gated convolution에 의한 여러 scale의 coarse sub-network outputs의 장점을 통합하기 위해 refinement sub-network을 계단식으로 설계한다.
기여점은 다음과 같다.
- Degradated document image에서 text extraction을 gated convolution의 gating value 학습으로 변환한다. Priori mask와 edge map을 통하여 gating value 학습을 약하게 유도할 수 있으며, 이는 stroke extraction 성능을 향상시킨다.
- GDB를 제안한다. Gated convolution을 통해 모델은 maks, edge map을 조정하여 refined stroke edges를 생성한다. Edge information 처리에 초점을 맞추기 위해 additional edge branch가 제안된다.
- 학습된 gating value가 다른 stroke feature로 전파하는 것을 통하여 stroke edge의 fine extraction과 background noise 억제에 기여한다는 것을 보여준다.
2. Related Work
2.1. Gated convolutions
게이트 컨볼루션은 의미론적 분할[19, 43, 49], 이미지 생성[47], 이미지 인페인팅[51] 및 기타 많은 작업[3,4,41]에서 광범위하게 탐구되었다. 예를 들어, 타키카와 외. [43] 고전적 스트림의 상위 레벨 기능을 사용하여 형상 스트림의 하위 레벨 기능을 게이트하는 새로운 유형의 의미 분할 게이트를 가진 새로운 2 스트림 아키텍처를 제안한다. [19]에서, 게이트를 사용하여 유효한 정보를 충분히 활용하기 위해 다른 계층의 기능을 선택적으로 융합하는 의미론적 세분화를 위해 GFF(Gateed Full Fusion)가 제안된다. [49]에서 Wang 등은 의미론적 분할에서 스케일 인식 다중 스케일 기능을 추출하는 성능을 향상시키는 새로운 모듈 GSTO(Gated Scale Transfer Operation)를 제안한다. 유효한 픽셀과 유효하지 않은 픽셀을 구별하는 바닐라 컨볼루션의 불가능성을 해결하기 위해 Yu 등. [51] 자유형 마스크를 사용한 이미지 인페인팅을 위해 게이트 컨볼루션을 활용한다. 문서 이진화는 텍스트와 배경을 구별하기 위해 회색의 두 가지 음영을 사용하는 것을 목표로 하며, 이는 의미론적 분할의 목표와 유사하다. 우리의 경우, 우리는 스트로크 에지의 추출을 세분화하고 배경에서 다양한 유형의 노이즈를 제거하기 위해 노이즈 마스크와 에지가 있는 게이트 컨볼루션을 입력으로 사용한다.
2.2. Document binarization
일반적으로, 문서 이진화 방법은 전통적인 임계값 기반 알고리즘과 딥 러닝 기반 방법의 두 가지 유형으로 나눌 수 있다[10, 42].
기존 임계값 기반 알고리즘
Otsu의 방법 [28]은 전체 문서 이미지에 대한 전역 임계값을 계산하는 반면, Niblack [24] 및 Saubola [38]를 포함한 로컬 임계값 방법은 로컬 패치의 통계 정보를 기반으로 픽셀 단위 임계값을 계산한다. [21]에서 로컬 임계값은 배경 추정에 의해 검출된 텍스트 스트로크 에지를 기반으로 계산됩니다. AdOtsu[6]는 추정된 배경 지도로 텍스트와 배경을 구별하는 Otsu 방법의 적응형 형태를 도입한다. How [12]는 이진화 알고리듬의 매개 변수를 조정하기 위한 자동 기술을 도입한다. Jia 등[14,15]은 배경 보상 이미지의 구조적 대칭 픽셀을 활용하여 이웃의 로컬 임계값을 계산한다. 이러한 전통적인 방법은 특정한 경험적 매개 변수를 필요로 하며, 이는 낮은 품질의 문서 이미지에서 일반화와 성능을 제한한다.
딥러닝 기반 방법
전체 컨볼루션 네트워크(FCN)는 문서 이진화에서 광범위하게 탐구되었다. Tensmeyer와 Martinez[45]는 문서 이진화를 위해 여러 척도를 결합한 새로운 FCN 아키텍처를 적용한다. DeepOtsu[9]는 반복적인 정교함과 스택 정교함으로 배경 소음을 반복적으로 제거하고 스트로크를 추출한다. 자오 외. [52] Pix2Pix[13]에 기반한 2단계 계단식 조건부 생성 적대 네트워크를 제안한다. 그와 쇼메이커[10]는 문서 향상 및 이진화 작업을 모두 학습하기 위해 CT-Net이라는 계단식 T자형 네트워크를 제안한다. [16]에서, 손으로 쓴 텍스트 인식기는 텍스트 의미 정보를 활용하기 위해 cGAN의 아키텍처와 통합된다. [42]에서, Suh 등은 문서 이미지 향상을 위해 EfficientNet[44]을 기반으로 하는 2단계 색상 독립 생성 적대 네트워크를 제안한다.3. Method
GDB의 전반적인 구조는 figure 2와 같다. GDB는 coarse-to-refine generator와 두 개의 discriminator로 설계된다.

Generator는 multi-branch coarse sub-network G_C와 refinement sub-network G_R을 포함한다. 첫번째로, G_C는 3개의 image(I_p, I_m, I_e)를 input으로 받고, 여기서 I_p는 original image에서 잘라낸 patch이고, I_m은 Otsu의 방법에 의해 생성된 noise mask이며, I_e는 Sobel Edge Detector에 의해 생성된 edge gradient map이다. 두 개의 upsampling branch는 각각 mask O^C_m과 edge O^C_e를 예측한다. 또한 loacl 및 global feature를 결합한 multiscale operation은 global mask O^C_gm을 병렬로 예측한다. 두 번째로, G_R은 4개의 image(I_grey, O^C_m, O^C_e, O^C_gm)를 input으로 가져간다. 여기서 I_grey는 I_p의 gray scale이며, sharp edge로써 finer binarization 결과를 예측한다. 그런 다음 두 단계에서 생성된 mask는 각각 discriminator를 통해 real mask와 판별된다.
3.1. Gated Convolutional Layer
Vanila convolution과 달리 gated convolution은 input mask(grey scale map)를 기반으로 다른 채널의 feature map에서 spatial location마다 가중치를 곱하여 foreground pixel과 background pixel을 구별할 수 있다. 이 메커니즘은 학습 과정 중 mask를 동적으로 업데이트하고 extra edge channel(grey scale map)로 이미지 생성 효과를 guide할 수 있다. Gated convolution은 다음과 같이 공식화될 수 있다,

W_g, W_f : 학습 가능한 convolution filters, σ : sigmoid activation, φ : non-linear activation (ReLU,ELU,...) Degraded documnet image에서 mask와 edge는 기존 알고리즘을 통해 간단히 얻을 수 있다. 이 논문의 목표는 노이즈가 많은 mask와 edge를 활용하여 gating value을 통해 coarse sub-network의 feature extraction을 weakly guide 하는 것이다. 두 번째 단계에서는, stroke edge를 더 미세하게 추출할 수 있으며, 첫 번째 단계에서 생성된 cleaner mask, edge들을 input으로 사용함으로써 background noise를 더 잘 제거할 수 있다.
각 gating value는 0 ~ 1 사이 값이며, 이는 feature map에서 서로 다른 spatial location의 pixel 값에 대한 attention 정도를 의미한다. Figure 3에서 이렇게 학습된 gating value의 시각화를 확인할 수 있다.

Gating value를 나타내는 각 saliency map(돌출부 맵)은 관심 영역이 더 높은 gating value를 갖는 feature map의 다른 영역을 강조한다. 예를 들어, saliency map (7)은 텍스트 영역과 관련이 있는 반면, 동일한 layer의 saliency map (8)은 bleed-through noise에 초점을 맞춘다. 이상적으로, 각 saliency map은 두 개의 구별되는 영역을 구별하기 위해 0과 1로만 구성되지만, 학습된 gating value에는 모호성(ambiguous)이 있다. 예를 들어, bleed-through nosie와 텍스트는 saliency map (3)에서 상대적으로 높은 gating value를 갖는다. 그러나 background 또는 텍스트 gating value이 노이즈보다 1에 가깝다면 학습된 gating value이 모호하더라도 노이즈를 효과적으로 억제할 수 있다. 이것은 deep network를 통과할 때 gating value가 하나에 더 가까운 feature만 유지되기 때문이다. Figure 3과 같이, 각 saliencyt map의 텍스트나 배경보다 bleed-through noise가 덜 중요하다. 따라서 학습된 gating value가 나오는 layer가 깊을수록 노이즈가 적다.

이 네트워크의 두 번째 layer에서 학습된 gating value를 greyscale map으로 변환한다. Figure 3에서 볼 수 있듯이, 학습된 gating value는 서로 다른 feature을 gate한다. Gating (b)는 stroke edge feature의 전파를 게이트하는 stroke edge feature extraction에 초점을 맞춘다. Gating (c)는 gating value를 0에 가깝게 설정하여 bleed-through noise를 필터링한다. Gating (d)는 텍스트와 배경의 semantic segmentation으로 해석될 수 있다. Input(mask, edge)의 priori information를 제외하고는 학습 중에 gating value가 supervise되지 않았다는 점이 중요하다.

3.2. Multi-branch coarse sub-network
Multi-brach coarse sub-network는 encoder-decoder FCN 처럼 설계되었다. Input(I_p, I_m, I_e)은 4개의 gated convolutional layer와 여러 gated residual block에 의해 인코딩된다. Decoding을 위해 두 branch는 5개의 upsampling gated deconvolutional layer와 동일한 아키텍처를 사용한다. Encoder와 decoder는 4개의 skip connection을 통해 계단식(cascaded)으로 연결된다. Output O^C_m, O^C_e는 I_m, I_e의 향상된 버전으로 볼 수 있다.
작은 patch를 사용한 local perdiction에는 많은 제한이 있다. Document image에서 연속된 노이즈 영역이 큰 경우, receptive field의 제한으로 인해 background pixel이 텍스트 pixel로 잘못 분류되는 경우가 존재한다. 기존연구를 통해 Local 및 global feature을 결합하면 noise suppresion 성능을 높일 수 있다는 사실은 입증되어 있다. 따라서, 전체 document image의 크기를 256x256으로 조정한다. Mask I_fm과 edge I_fe는 크기가 조정된 전체 image I_f를 통해 동일한 방법으로 획득된다. Figure 2의 하단과 같이, multi-branch coarse sub-network는 input(I_f, I_fm, I_fe)을 병렬로 처리한다. 다음으로, 예측된 mask O^C_ fm은 원래 이미지와 동일한 크기로 크기가 조정된 다음 주어진 (x,y) 좌표에 따라 잘라내어 global 정보를 포함하는 global mask patch O^C_gm을 얻는다.3.3. Refinement sub-network
Multi-scale fusion과 충분한 supervision의 부족으로 인해 coarse sub-network는 background noise가 제거되지 않는 문제에 직면하며, 이는 input mask I_m, egde I_e의 stroke과 noise의 일부를 포함한 결과물을 생성해낸다. 따라서, 이러한 문제를 해결하기 위해 refinement sub-network를 cascaded 형식으로 붙인다. Refinement sub-network의 작업은 1단계의 output의 장점을 multi-sclae로 통합하는 방법을 학습하는 것이다. Receptive field를 확대하기 위해 dilated convolution를 활용한다.
Coarse sub-network와 refinement sub-network는 coarse가 RGB patch를 포함하는 반면 refinement가 greyscale이라는 점을 제외하고는 input이 유사하다. 두 단계에서 mask와 edge는 binarization 성능을 향상시키기 위한 추가 정보로 사용된다. Input mask와 edge가 실제에 가까울수록 네트워크는 binarization 결과를 더 정확하게 예측할 수 있다. Refinement sub-network는 coarse sub-network에 의해 깨끗해진 mask와 edge를 input으로 사용하므로, encoder는 노이즈의 영향을 덜 받을 수 있다. 결과적으로 noise을 제거하고 stroke를 효과적으로 복원할 수 있다.
3.4. Discriminator
두 단계에 해당하는 두 discriminator D_C와 D_R은 SN-PatchGAN과 동일한 아키텍처를 공유한다. GAN의 학습 불안정성으로 인해 SN-GAN은 spectral normalizatoin을 GAN의 학습 프로세스에 적용하여 discriminator가 Lipschitz constraint를 충족하여 매개 변수의 급격한 변화를 제한한다. PatchGAN은 patch scale의 구조에만 penalty를 준다. SN-PatchGAN은 이 두 가지 기술을 하나로 결합한다. 우리는 markovian patch의 feature를 포착하기 위해 6개의 convolution을 쌓는다. Discriminator의 input은 degraded document image와 쌍을 이룬 binarization image 간의 4- channel concatenation이다.
3.5. Loss functions
Original image, patch I_p, mask I_m 및 edge I_e, coarse sub-network, refinement sub-network는 각각 O^C_m, O^C_e, O^C_fm 및 O^R_m을 예측하며, 여기서 O^R_m은 최종 binarization 결과이다.
Ground truth(T_f, T_fr, T_m, T_e)는 다음과 같다. 여기서 T_f는 전체 binarization map의 gt(텍스트의 경우 1, 배경의 경우 0)이고, T_fr은 Tf의 256*256으로 크기가 조정된 것이고, T_m은 T_f에서 잘라낸 패치이며, T_e는 T_m의 Sobel edge detection 결과이다. Multiscale 작업에서는 원래 크기의 mask O^C_fm도 penalty를 받는다.
GDB 학습에는 dice loss, binary cross-entropy loss, L1 loss, adversarial loss가 사용된다. 공식의 단순함을 위해 변수들은 아래와 같이 정리한다.
- Coarse sub-network의 input I^C : {I_p, I_m, I_e}
- Coarse sub-network의 input I^C_f : {I_f, I_fm, I_fe}
- Coarse sub-network의 output O : {O^C_m, O^C_e, O^C_fm, O^R_m}
- Ground-truth T : {T_m, T_e, T_f, T_m}
학습 샘플의 불균형으로 인해 텍스트가 patch의 작은 부분만 차지하는 경우를 위해 dice loss를 활용한다. 또한 학습 안정성을 위한 binary cross-entropy loss을 함께 사용하며 다음과 같다.
해당 patch가 pure background일 때에는 gradient를 넘기지 않고 dice loss를 유지하기 위해 텍스트와 background pixel value를 뒤집는다.

N : pixel 수, {λ_i} = {1,1,1,2} 또한, generation ambiguity를 줄이고 pixel level consistency를 강제하기 위해 L1 loss를 추가로 아래와 같이 사용한다.

Adversarial loss의 경우, 다음과 같이 정의된 Markovian patch에 penalty를 주기 위한 hinge loss를 사용한다.

G : Generator, D : Discriminator, z : G's input, x : real image 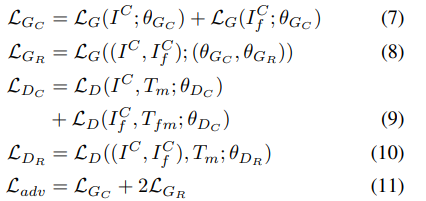
여기서 G_C는 multi-branch coarse sub-network, G_R은 refinement sub-network, D_C와 D_R은 각각 해당하는 discriminator이다.
Generator의 total loss는 다음과 같다.

여기서 λ_d, λ_b, λ_L1, λ_a는 각각 1, 1, 10, 0.1로 설정된 dice, binary cross-entropy, L1, adversarial loss 간의 균형을 맞추기 위한 가중치이다. 두 generator를 별도로 훈련할 필요 없는 end-to-end로 학습이 이루어진다.
paper : https://arxiv.org/abs/2302.02073
'Paper Review > Generative Model' 카테고리의 다른 글