-
[논문 리뷰] Multi-Concept Customization of Text-to-Image Diffusion (2023 ICCV)Paper Review/Generative Model 2023. 11. 2. 20:18
1. Introduction
최근 다양한 text-to-image 모델들은 고품질의 이미지 생성과 대형 사전학습 모델로 인한 다양한 클래스의 객체들을 원하는 텍스트 프롬프트를 통해 생성해낸다. 하지만, 이러한 대형 생성 모델의 일반화 능력에도 불구하고, 사용자들에게 최적화된 개념을 모델에 통합시키는 것은 도전적인 작업이다. 예를 들어, 사용자들의 가족, 친구, 애완동물과 같은 개인화된 개념들은 모델 학습에 포함되지 않기 때문에, 모델 학습 후 텍스트 프롬프트만으로 이러한 개념을 추론하는 것은 불가능하다.

학습되지 않은 범주의 객체에 대한 성공적인 생성 예시. 본 연구는 개인화 범주를 새로운 수식어 토큰 V*으로 나타낸다. 따라서, 저자들은 개인화된 text-image diffusion model의 fine-tuning 기술인 Custom Diffusion을 제안한다. 개인화 능력을 부여하기 위해, 제안한 모델에서는 모델 가중치의 하위 집합인 cross-attention layer의 텍스트에서 잠재적 특징으로의 key, value 매핑을 fine-tuning한다. 목표 이미지와 유사한 캡션을 가진 4장 이하의 적은 수의 이미지셋에 대한 업데이트만으로 diffusion model의 개인화 능력을 향상시킨다. 이러한 방법을 기반으로 Custom Diffusion은 전체 모델 가중치의 3%만을 업데이트하면서 fine-tuning 시간을(A100 2대에서 6분) 단축시킨다.
2. Method

Custom Diffusion의 fine-tuning은 위와 같이 모델의 cross-attention layer에서 가중치만을 업데이트한다. 또한 새로운 개념에 대한 과적합을 방지하기 위해 실제 이미지의 정규화 세트를 사용한다.
2.1. Single-Concept Fine-tuning
사전 학습된 text-to-image diffusion model이 주어지면, 4개 이하의 이미지와 해당 텍스트 설명을 통해 새로운 개념을 주어진 모델에 포함시키는 것을 목표로 한다. Fine-tuning된 모델은 사전 학습시 얻은 지식을 유지해야 하며, 텍스트 프롬프트를 기반으로 새로운 개념을 허용할 수 있어야 한다.
본 연구에서는 LDM을 base model로 활용한다. LDM은 autoencoder 구조를 통해 이미지를 잠재 표현으로 인코딩한다. 그 이후, cross attention을 통해 모델에 주입된 텍스트를 조건으로 잠재 표현에 대한 diffusion model을 학습한다.Learning objective of diffusion models.
Diffusion models은 아래와 같이 학습 데이터 분포 q(x_0)를 p_θ(x_0)로 근사화하는 것을 목표로 한다

여기서 x_1 ~ x_T는 순방향 마르코프 체인 s.t. xt = √ αtx0 + √ 1 - αt ϵ의 잠재 변수를 의미한다. 모델은 1000 timestep에 대한 마르코프 체인의 역과정을 학습한다. 특정 timestep t에서 노이즈 이미지 x_t가 주어지면 모델은 x_(t-1)을 얻기 위해 입력 이미지로부터 노이즈를 제거하는 것을 학습하는 것으로 볼 수 있다. 따라서 최종 학습은 아래와 같이 단순화할 수 있다.

여기서 ϵ_θ는 모델의 예측이고 w_t는 손실에 대한 시간 의존적 가중치를 의미한다. 모델은 timestep t에 따라 조정되며
다른 모달리티 c, 예를 들어 텍스트에 따라 추가로 조정될 수 있다. 추론하는 동안 모델을 사용하여 정해진 timestep에 대해 무작위 가우시안 노이즈 이미지 x_T가 노이즈화된다. Fine-tuning 목표를 위해 주어진 텍스트 이미지 쌍에 대해 식 (2)에서 손실을 최소화하도록 모든 계층을 업데이트한다. 이는 대규모 모델에 대해 계산적으로 비효율적일 수 있으며 몇 개의 이미지에 대해 훈련할 때 과적합으로 쉽게 이어질 수 있으므로 본 연구에서는 fine-tuning에 충분한 정도의 최소 가중치만을 업데이트 시킨다.
Rate of change of weights.
사전학습된 모델의 파라미터는 아래와 같이 크게 3가지 layer에서 발생한다.
- Cross-attention layer(텍스트와 이미지 사이)
- Self-attention (이미지)
- Diffusion model 내부 U-Net layer

Figure 3은 모델 학습 중 각 layer의 가중치 변화율의 평균값을 보여준다. 여기서 알 수 있듯이 Cross-attention layer에서 파라미터는 나머지 파라미터에 비해 상대적으로 높은 변화율을 갖는다. 높은 변화율에 반해 CA layer의 파라미터 개수는 전체 파라미터의 5%에 불과하다. 이는 fine-tuning에 중요한 역할을 한다는 것을 시사하며, 이를 업데이트하는 것을 목표로 한다.
Model fine-tuning.
Cross-attention block은 text-to-image diffusion model에서 텍스트 특징에 따라 네트워크의 잠재적 특징을 수정한다. 텍스트 특징 c 와 잠재 이미지 특징 f 가 주어졌을 때, single-head cross-attention 연산은 아래와 같이 Q = W^q f, K = W^k c, V = W^v c에 대한 weighted sum으로 구성된다.

여기서 Wq, Wk, Wv는 입력을 각각 쿼리, 키, 값 특징에 매핑되고 d'는 키 및 쿼리의 출력 차원을 의미한다. 잠재 표현은 이후 attention block의 출력으로 업데이트된다. Fine-tuning은 주어진 텍스트에서 이미지 분포로의 매핑을 업데이트하는 것을 목표로 하며, 텍스트 특징은 CA block의 W^, W^v의 projection matrix에만 입력된다. 따라서 본 연구에서는 아래와 같이 fine-tuning 과정에서 diffusion model의 W^k 및 W^v 파라미터만 업데이트할 것을 제안한다.

Text encoding.
주어진 대상에 대한 개념 이미지가 주어지면 텍스트 캡션도 필요하다. 대상 개념이 일반 범주의 고유한 인스턴스(예: 애완견)인 경우 개인화 작업을 위해 새로운 수식어 토큰 임베딩, 즉 V ∗ 을 도입한다. 학습 중 V ∗는 rare occurring token embedding으로 초기화되고 CA layer 파라미터와 함께 최적화된다.
Regularization dataset.

대상 개념 및 텍스트 캡션 쌍을 fine-tuning하면 language drift 문제가 발생할 수 있다고 한다.예를 들어, "moongate"에 대한 학습은 모델이 위와 같이 이전에 학습된 시각적 개념과의 "moon"과 "gate"의 연관성을 잊게 되는 것이다. 이를 방지하기 위해 CLIP 텍스트 인코더 특징 공간의 임계값 0.85 이상의 유사성을 갖는 LAION-400M 데이터 세트에서 200개의 정규화 이미지 세트를 선택하여 사용한다고 한다. 이는 대상 텍스트 프롬프트와 유사성이 높은 캡션을 갖는 것으로 볼 수 있다.
2.2. Multiple-Concept Compositional Fine-tuning
Joint training on multiple concepts.
여러 개념을 적용하여 fine-tuning하기 위해 각 개별 개념에 대한 학습 데이터를 결합하고 공동으로 학습시킨다. 대상 개념을 나타내기 위해 드물게 발생하는 다른 토큰으로 초기화된 다른 수식어인 V∗_i를 사용하고 각 계층에 대한 cross-attention key, value 행렬과 함께 최적화한다. 이렇게 가중치 업데이트를 cross-attention의 key, value의 파라미터로 제한하면 모든 가중치를 업데이트하는 DreamBooth와 같은 방법에 비해 두 개념을 구성하는 데 훨씬 더 나은 결과를 얻을 수 있다.
Constrained optimization to merge concepts.
제안한 방법은 텍스트 특징에 대응하는 key, value의 projection matrix만 업데이트하므로 multiple fine-tuned 개념으로 생성할 수 있도록 후처리 작업으로 이들을 병합할 수 있다. 집합 {W^k_(0,l),W^v_(0,l)} 사전학습된 모델의 모든 L개의 cross-attention layer에 대한 key, value matrix를 나타내고 {W^k(n,l), W^v_(n,l)} 이 추가된 개념 n ∈ {1 · · N}에 대해 업데이트된 matrix을 나타낸다고 가정한다. 후속 최적화는 모든 layer와 key, value matrix에 적용되므로 표기법의 명확성을 위해 위첨자 {k,v}와 계층 l을 생략한다. 최종적으로 구성 목표를 아래와 같이 constrained least squares problem으로 공식화한다.

여기서 C ∈ R^(sxd)는 차원 d의 텍스트 특징을 의미한다. 이것들은 모든 N개의 개념에 걸쳐 s개의 목표 단어들로 구성되며, 각 개념에 대한 모든 캡션들은 flattened되고 concat된다. 이와 유사하게, C_reg ∈ R^(s_reg x d)는 정규화를 위해 랜덤으로 샘플링된 ~1000개의 캡션들의 텍스트 특징들로 구성된다. 직관적으로, 위의 공식은 원래 모델의 행렬들을 업데이트하여 C의 목표 캡션들의 단어들이 fine-tuning된 개념 행렬들로부터 얻은 값들과 일관성 있게 매핑되는 것을 목표로 한다. 위의 식은 Lagrange multipliers를 사용하여 closed-form으로 해결할 수 있다고 한다.
이러한 최적화 기반 방법은 각 개별 fine-tuning 모델이 있는 경우 더 빠르며, 단일 이미지에서 두 가지의 새로운 개념이 일관되게 생성될 수 있도록 한다.
3. Expermients
- 데이터셋
- 10가지의 새로운 개념에 대한 타겟 데이터셋 , CustomConcept 101(101개의 새로운 개념으로 이루어진 데이터셋)
3.1. Single-Concept Fine-tuning Results
Qualitative evaluation

새로운 개념에 대한 어려운 프롬프트에 대해 각 fine-tuning model을 테스트한다. 여기에는 새로운 장면, 예술 스타일로 대상 개념을 생성하고, 대상 개념의 특정 속성(예: 색상, 모양 또는 표현)을 변경하는 것이 포함된다. 위 그림에서 볼 수 있듯이 Custom Diffusion은 대상 객체의 시각적 세부 사항을 캡처하는 동시에 높은 텍스트 이미지 정렬 성능을 보인다. Textal Inversion보다 성능이 뛰어나며, 낮은 훈련 시간과 모델 스토리지(약 5배 빠르고 75MB 대 3GB 스토리지)를 가지면서 DreamBooth와 비슷한 성능을 보인다.
Quantitative evaluation.
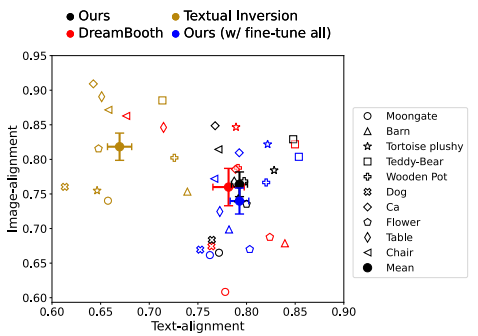
각 데이터 세트에 대해 20개의 텍스트 프롬프트와 프롬프트당 50개의 샘플을 평가하여 총 1000개의 생성된 이미지를 생성하여 평가한다. 모든 방법에 걸쳐 50 timestep의 DDPM 샘플링과 6 classifier-free guidance scale을 사용한다. Custom Diffusion은 계산 및 시간 효율성을 높이면서 diffusion model의 모든 가중치를 fine-tuning하는 기존 모델과 비슷한 성능을 보인다.

위 표는 fine-tuning 된 개념과 유사한 캡션으로 reference 데이터 세트의 각 fine-tuning 모델에 의해 생성된 이미지의 KID를 보여준다. Custom diffusion은 기존 모델보다 KID가 낮으므로 목표 개념에 덜 과적합되었음을 시사한다.
3.2. Multiple-Concept Fine-tuning Results

각 개념에 대해 두 개의 서로 다른 [V1] 및 [V2] 토큰을 사용하여 두 데이터 세트에 대한 DreamBooth 학습과 방법을 비교한다. Text Inversion의 경우 동일한 문장에서 각 개념에 대해 개별적으로 fine-tunined token을 사용하여 추론을 수행한다. Custom Diffusion의 결과는 CA 파라미터만 업데이트하는 fine-tuning 방법의 효과성을 보여준다.
Prompt-to-prompt results

Custom Diffusion with artistic styles.

4. Discussion and Limitations
결론적으로, 소수의 이미지 예제를 사용하여 새로운 개념, 범주, 개인 객체 또는 예술적 스타일에 대한 대규모 text-to-image diffusion model의 fine-tuning 방법을 제안하였다. 이러한 계산 효율적인 방법은 대상 이미지와의 시각적 유사성을 유지하면서 새로운 맥락에서 fine-tuned 개념의 새로운 변형을 생성할 수 있다. 또한, 우리는 모델 가중치의 작은 부분만을 업데이트 하며 계산 효율적임을 입증한다.

하지만, 위 그림과 같이, 애완견과 애완 고양이와 같은 어려운 구성은 여전히 도전적이다. 또한, 세 개 이상의 개념을 함께 적용하는 것도 어렵다.
'Paper Review > Generative Model' 카테고리의 다른 글